EVENT AGENDA
Event times below are displayed in PT.
Systems @Scale is a technical conference for engineers that manage large-scale information systems serving millions of people. The operation of large-scale systems often introduces complex, unprecedented engineering challenges. The @Scale community focuses on bringing people together to discuss these challenges and collaborate on the development of new solutions.
The 2021 series will be hosted virtually. Joining us are speakers from Facebook, Stanford, VMWare, Google, and Temporal, with topics spanning queuing, workflows, shared storage fabric, consistency@scale and consensus protocols in the context of large-scale distributed systems.
Starting February 24th, for four weeks, we will share the topics via a blog post on Monday followed by a recorded session and live Q&A on Wednesdays.
Event times below are displayed in PT.
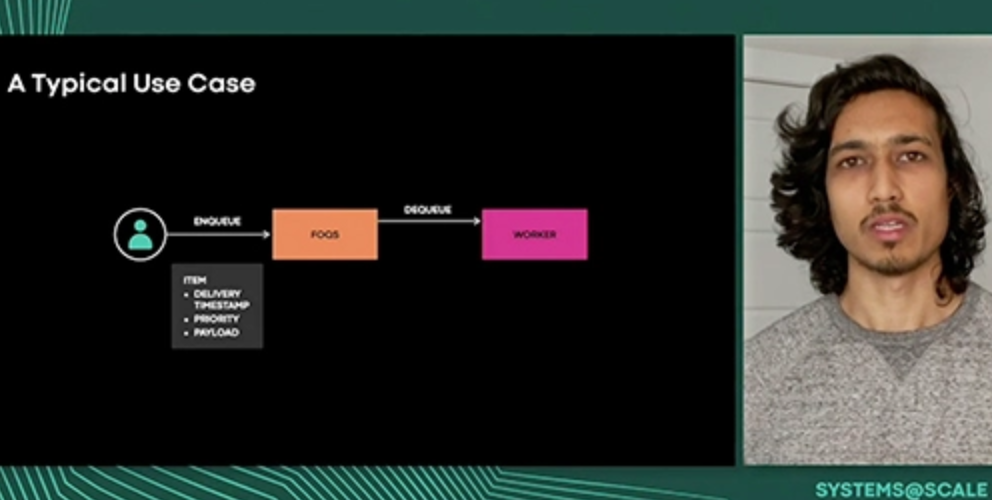
Facebook Ordered Queue Service (FOQS) is a distributed priority queue that powers 100s of microservices across the Facebook stack. Use cases of FOQS range from video infra, to data infra, to ai infra, to many others. FOQS is horizontally scalable and supports rich semantics such as deferred delivery and ordering by a 32 bit priority. FOQS was conceived about 3 years ago to be a job queue. Since then, FOQS has seen exponential growth and now processes close to 700 billion items per day. In this talk, we present why we built FOQS, FOQS' architecture, and some of the scaling challenges that we have solved and have yet to solve. In particular, we will look at some of the complexities that come with building a globally distributed queue to handle Facebook's scale.


Building a 300 miles per hour production car is hard. Speed is not a linear measurement, even though you think of it that way. Taking a car from 150mph to 300mph requires eight times more power, or O(n^3) in our language, which is incredibly challenging. And there is a lot more to it than power. Pushing the maximum of a single replicated RabbitMQ queue from 25k messages per second to 1 million took a lot more than better algorithms. And no, we didn't change the programming language or the code VM. In order to understand this, we first need to have a clear picture of the building blocks and what the limits are. Next, we look at the solution, and conclude by identifying the upcoming developments in the wider technology sector. They will help us build faster and more efficient queueing systems. You can contribute by attending this talk, trying out what team RabbitMQ has built for 2021, and sharing your ideas on how to make it even better. We are better together.

Facebook has its own BLOB Storage infrastructure that is responsible for storing trillions of BLOBs. For the Storage Infrastructure these objects are just random bytes of different sizes, which have to be stored reliably. At the user level, however, they could be the representation of a picture or video that they have uploaded to Facebook. Each picture or video that gets uploaded by a user goes through several processing pipelines, which can produce multiple different logically equivalent representations of the same entity. e.g. a video might be transcoded into multiple encodings with different resolutions/codecs. Although these encodings are different blobs, they represent the same video and any of these can be served to users, based on various parameters like network speed, available codecs and so on. In that context, the blobs could potentially be related. These different blobs representing the same logical object are called ‘Semantic Replicas’. Given that any of the Semantic Replicas can be served to the user, we can improve the availability & read reliability of the logical asset by storing different Semantic Replicas in different failure domains. In case of videos, not all videos are equal. Some videos get watched more than others and the probability of a video being watched reduces significantly over time. This information can be used to store videos more efficiently and reduce the storage cost per byte while maintaining the user experience. Chidambaram and Dan will talk about end-2-end architecture of the systems being built to achieve optimizations across Facebook stack that enhance user experience and lower the storage cost per byte.


Every business needs a robust backup and disaster recovery (DR) solution. DR has always been expensive, complex, and error prone. We have converted this complex backup and DR process into a simple to use SaaS solution. Solving this problem required a new type of multi-purpose cloud filesystem. In this session, we briefly describe the business problem, and dive into the design of our cloud filesystem.

At Facebook, several large-scale distributed applications like distributed video encoding and machine learning require a series of steps to be performed with dependencies between those. Building and operating large scale distributed systems is a hard problem in itself - hard to develop for, to reason about, and to debug. One way to deal with this complexity is to raise the level of abstraction and look at these problems which involve a series of steps to follow as workflows. A workflow framework is a way of keeping the complexity under control and let developers focus on the business process they care about. The workflow framework can take care of the heavy lifting around orchestration, debuggability, reliability, and state management. Dan Shiovitz and Girish Joshi will talk about the past, present, and future of workflows at Facebook: How several workflow systems have evolved at Facebook and cover the taxonomies and tradeoffs of workflow authoring styles they support; we will go over experiences from building a couple of general purpose workflow systems to cover broad workflow needs at Facebook, scaling those from zero to billions of workflows a day while staying reliable and observable and attempts and challenges to converge these general purpose workflow systems to a unified workflow system.


Temporal is a complex distributed system. But most of its complexity is not accidental. Maxim’s presentation reveals how the core design decisions resulted from applying first principles to satisfy the few basic requirements.

Facebook delivers fresh personalized content by performing a large number of reads to our online data store TAO. TAO is read optimized and handles billions of queries per second. To achieve high efficiency, organizational scalability, and optimize for different workloads, Facebook has traditionally relied on asynchronous replication which presents consistency challenges: application developers must handle or build guardrails against potentially stale reads. Historically, TAO alleviated this burden by providing read-your-writes (RYW) consistency by default using write-through caching. This strategy fell short as our social graph ecosystem expanded to include global secondary indexing as well as other backend data stores. We built FlightTracker to manage consistency for the social graph at Facebook. By decomposing the consistency problem, FlightTracker provides uniform semantics across heterogenous data stores. FlightTracker allowed us to evolve beyond write-through caching and fixed communication patterns for higher reliability for TAO. FlightTracker maintains the efficiency, latency, and availability advantages of async replication, preserves the decoupling of our systems, and achieves organization scalability. Through FlightTracker, we provide user-centric RYW as a baseline while allowing select use cases such as realtime pub-sub systems like GraphQL Subscriptions to obtain higher levels of consistency. This talk will introduce how FlightTracker provides RYW consistency at scale and focus on how FlightTracker works for global secondary indexing systems. For more details, please refer to our blog post or our paper in OSDI’20.


Delos is a control plane storage platform used within Facebook. Delos employs a novel technique called Virtual Consensus that allows any of its components to be replaced without downtime. Virtual Consensus enables rapid upgrades: engineers can evolve the system over time, making it faster, more efficient, and more reliable. Separately, Delos lowers the overhead of building and maintaining a database by providing a common platform for consensus and local storage that can be re-used across different top-level APIs. We currently run two Delos databases in production, DelosTable (a table store) and Zelos (a ZooKeeper clone); in the process, we amortize development cycles and operational know-how across the services, while benefiting from cross-cutting performance and reliability improvements.

Querying massive collections of events, sessions, and logs is expensive – and even moreso when slicing and dicing by the increasing number of dimensions attached to each piece of data (e.g., browser type, device, feature flag). In this talk, I'll describe how adapting a now-classic technique from distributed consistency – the design of commutative and associated data structures (e.g., CRDTs) – can simplify the problem of storing, querying, and centralizing large scale, high cardinality datasets. The resulting mergeable summaries provide useful, scalable primitives for answering complex queries – including frequent items, quantiles, and cardinality estimates – over high cardinality slices. In addition to introducing recent research on this topic, I'll discuss lessons from productionizing mergeable summaries at Microsoft and Sisu and in Apache Druid.

Spanner is Google's highly available, replicated SQL database. In this talk we'll explore how Spanner uses globally synchronized time (TrueTime) to provide applications external consistency and lockless consistent snapshot reads, its performance impact and how application can adjust their consistency expectations for better performance.