






Phil Lopreiato, Rahul Iyengar, Richard Ross, Jonathan Kaldor, and Gautam Sewani
As Meta’s infrastructure has grown into hyperscale, we need to be prepared for increasingly complicated failure scenarios. Some of them are software bugs, others are hardware issues, and even more are external events such as power or fiber outages. Increasingly complex failures also mean mitigation will be complicated, since it will involve more moving parts. Fortunately, Meta has a long history of investing in a Disaster Recovery program (DR), going all the way back to Hurricane Sandy in 2012, to ensure we are prepared when the unexpected happens.
Who we are
As the Web Foundation team, we operate Meta’s primary web tier, and work on full-stack reliability. The team is composed of cross-functional engineers who make sure the infrastructure behind the web tier is healthy and well designed. We jump into incident response, work on some of the most complex areas of the infrastructure, and help build whatever we need to keep the site happily up and running. Here, we’ll share a story about a time Meta averted a major outage but required using the full breadth of our incident response toolkit to recover from.
Meta’s DR program
Over the past decade, Meta has been investing in system design and tooling to ensure that we can recover from unexpected scenarios. Whether ensuring that databases are always backed up (and that the backups are recoverable!) or that we can always “drain” traffic from a suddenly unusable region, we run regular exercises to validate the tooling and process. We also build tooling to track the dependencies among systems and validate that there are no inversions that would prevent recovering from an outage. This ensures the tooling is trustworthy in practice, giving engineers the confidence to run it.
No matter how much we prepare, however, things don’t always go as planned. For example, take the major network outage that occurred in 2021. This incident highlighted the complexities of running massive-scale, globally distributed infrastructure systems. We learned a lot from this outage, especially regarding the ways various low-level systems interacted while recovering.
The incident
Meta’s infrastructure runs on top of “twine” (TW), the control plane for managing service containers across the fleet. Twine has an isolated control plane per cluster whose metadata lives in a Zelos ensemble. Twine too is self-hosted, and so the cluster-level control plane also runs in TW containers, managed by a set of separate scheduler instances (called “meta” schedulers). This arrangement is designed to be a low-dependency deployment that ensures the overall control plane is robust. However, a dependency inversion had snuck in, where one of the Zelos ensembles was managed by the cluster scheduler instead of the meta scheduler.
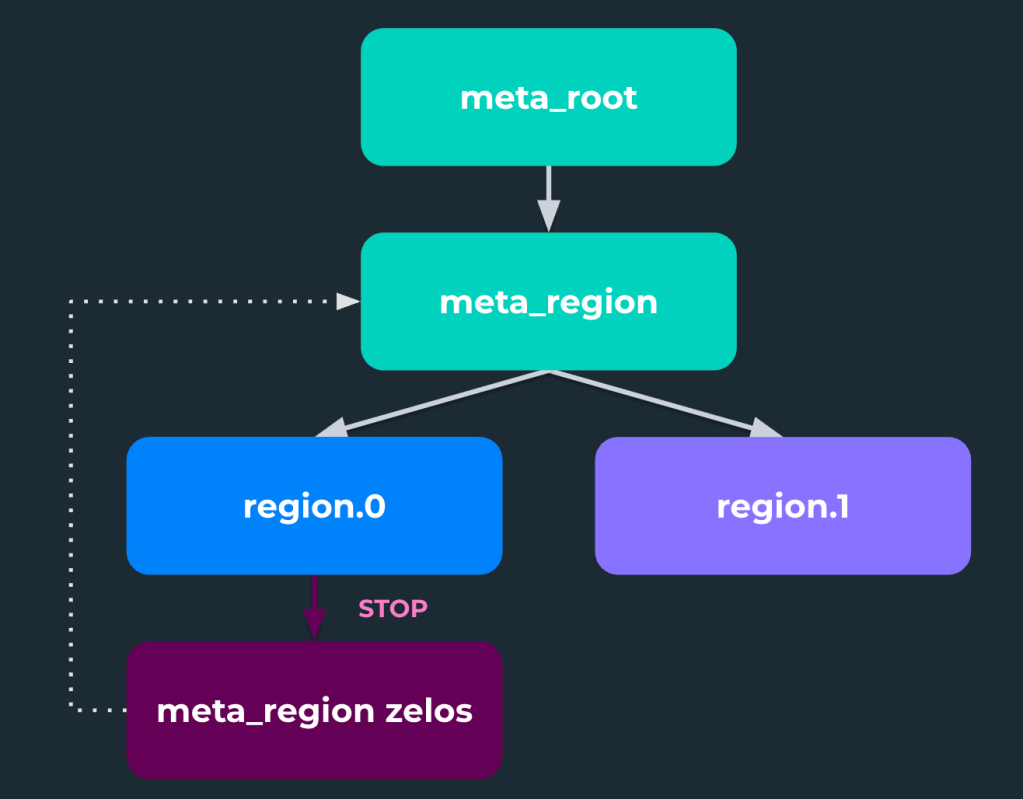
Figure 1. The initial “stop” command
This meant that when a software bug in the scheduler was deployed that resulted in the cluster scheduler incorrectly stopping running jobs, it also stopped one of the core Zelos ensembles (shown in Figure 1), which then broke the cluster scheduler itself (shown in Figure 2). This prevented us from reverting the change the normal way, as the scheduler itself was also stopped.
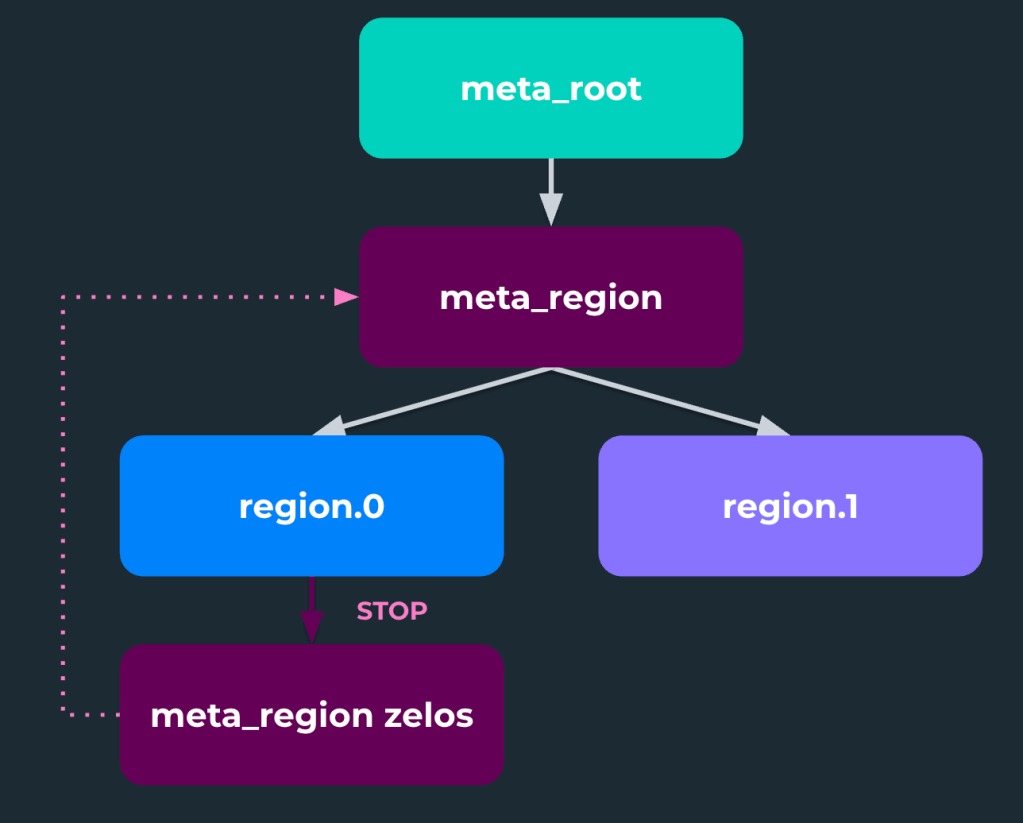
Figure 2. Stopping the zelos ensemble takes down the regional scheduler
One aside: Due to our investment in DR and utilization of staged rollout plans for all changes, this incident affected only a single data center (DC). We were able to quickly and confidently drain user traffic from the affected DC, redirecting it elsewhere. This meant that most users experienced only a short outage while the response team was able to continue the investigation.
Recovery
To bring the cluster scheduler back, we needed to use the “Belljar” tooling suite. The suite includes a way to spin up low-level containers in the absence of a healthy scheduler—exactly our problem.
Once we figured out which hosts were previously running the scheduler and got the right version of the service binary on the host, we were able to spin up a “recovery container” running the correct flags to disable the bad code path. This allowed the scheduler to start back up, take the lock on the control plane, and begin starting up all the downstream user jobs that were affected. Once the system recovered, we were able to run a standard revert of the original change and stop the recovery container, allowing the standard TW to manage the cluster. Finally, we could undrain the user traffic, fully restoring normal operation.
Fixing the dependency inversion
After that incident, we carefully evaluated how our dependencies were set up. In particular, we noticed the dependency inversion that had crept in: The Zelos ensemble used by the meta_region scheduler was managed by the cluster scheduler (see Figure 3).
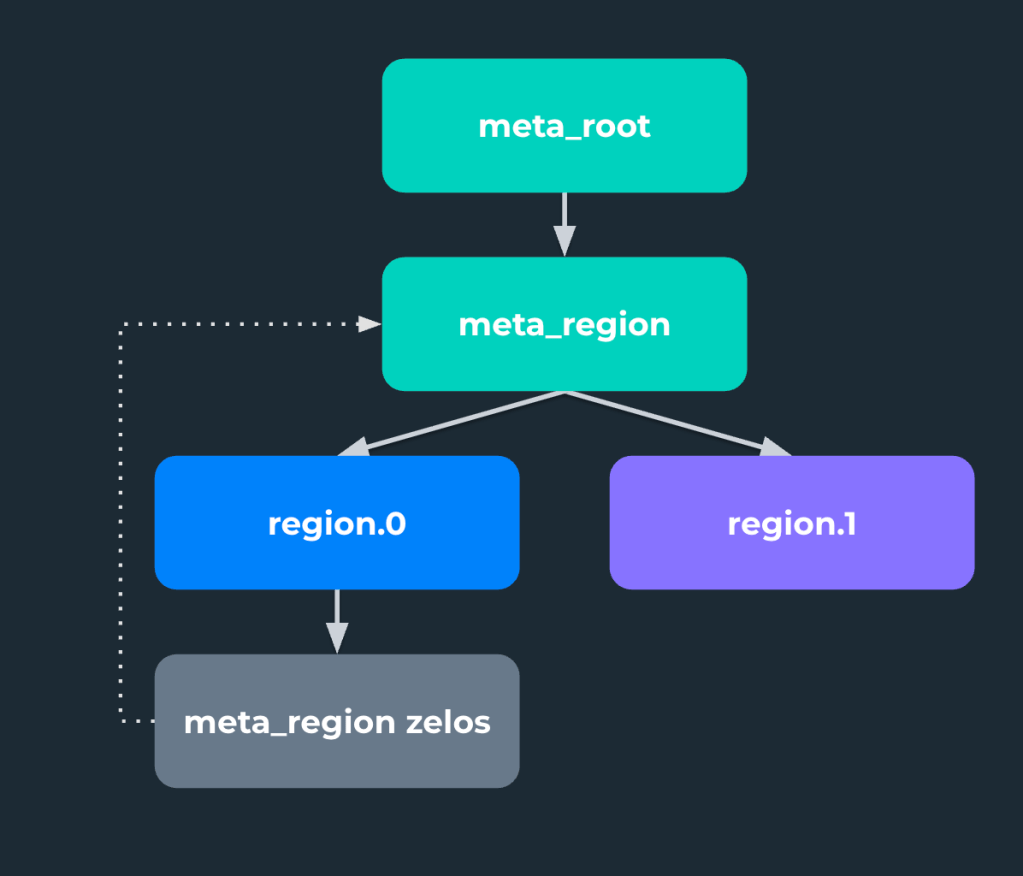
Figure 3. Dependency inversion between schedulers and Zelos ensemble
To address this, we moved the Zelos ensemble to be managed by meta_root scheduler, which made it a peer of the meta_region scheduler (see Figure 4), thus fixing the dependency inversion.
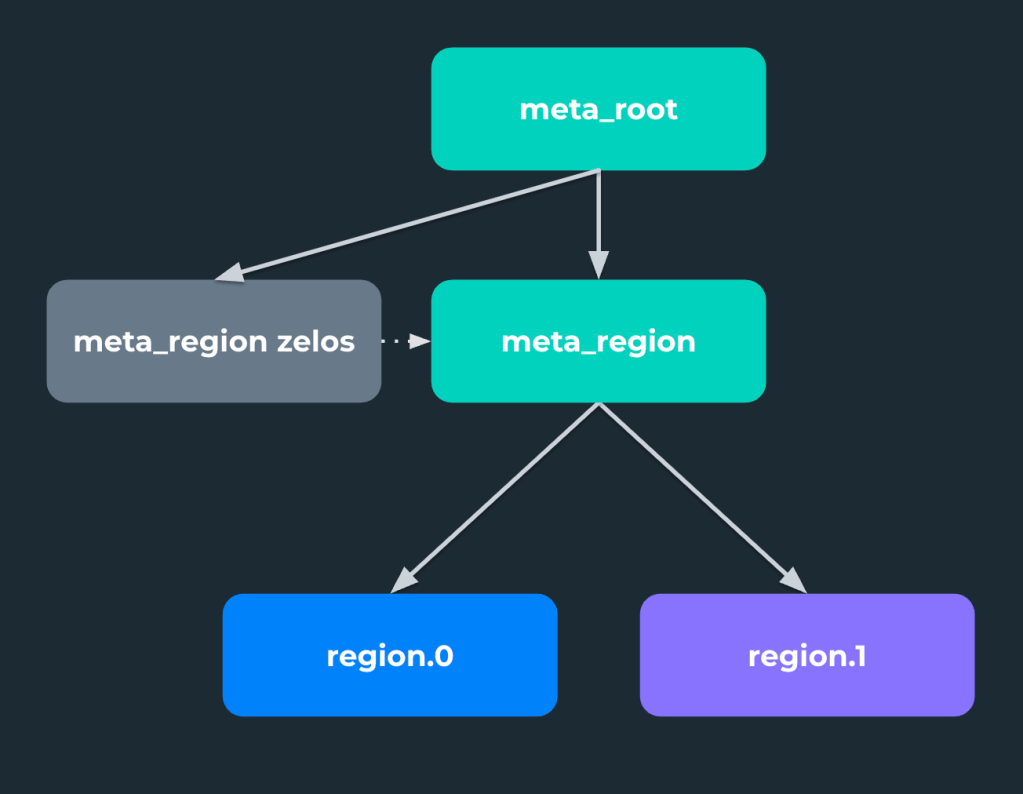
Figure 4. Updated dependency graph with “uplifted” zelos ensemble
Practice makes perfect
While we have automation and runbooks to continuously validate our recovery tooling, engineers rarely interact with them, because major infrastructure outages are so uncommon. This infrequent usage can impact the ability of engineers to confidently and correctly use this tooling, especially during stressful situations.
This is why we established regular, mandatory team drills, running through recovery scenarios using the Belljar tooling suite. These practice exercises allow engineers to gain familiarity and muscle memory with the recovery process in a low-stakes environment, ensuring that when a real incident occurs, the team is prepared to respond confidently and efficiently.
Takeaways
The primary lesson here is that investing in recovery tooling—and being comfortable using it in a stressful situation—is critical to running complex infrastructure. If we hadn’t anticipated the need to run low-level recovery containers outside of the normal orchestration, and hadn’t tested this process prior to actually needing it, this incident would have been substantially worse. We did have these tools in our toolbox, however, and were able to deploy them as needed, which prevented this incident from cascading into another massive outage.

